See High Availability Demo, Revised
Note 1: This article was edited on August 17, 2010, and so was the read-me file in the download, to fix the following two file names: 1_setup_HA.bat and 2_start_HA.bat.
Note 2: This article was edited on October 22, 2013 to update the download link. If you have any problems downloading the file, contact breck.carter@gmail.com.
Quick Start
1. If you don't already have SQL Anywhere 11 installed, download the Developer Edition.
2. Download demo HA V11 single machine.zip into c:\temp.
3. Unzip it using this password: rjOdagvFCChOXrfb
4. Run these Windows command files...1_setup_HA.bat 2_start_HA.bat 3_connect_HA.bat5. See $readme.txt for more things to do.
My previous post mentioned...
The World's Fastest Simplest And Most Complete
End-to-End
Single-Machine
Demonstration Of
SQL Anywhere High Availability... and here it is. But first, this disclaimer:Having said that, this article is all about the "teaching, learning and giving demonstrations"... and studying the behavior of a running High Availability (HA) setup. Not to mention getting practice getting the (somewhat funky) command line parameters right.
Except for the purposes of teaching, learning and giving demonstrations, I can see no justification whatsoever for using fewer than three physically separate computers to implement SQL Anywhere High Availability: two computers for the two copies of the database and a third to run the arbiter.
It's hard enough to eliminate all single points of failure; by putting two servers on one computer absolutely guarantees that one exists.
Let's plunge right in: Part 1 shows how to run the demo, followed by Part 2 which explains the bits and pieces.
Oops, one last thing...
The Assumptions
- This demo has been written for Windows.
- It assumes you have SQL Anywhere 11 installed; you can download the Developer Edition here.
- The demo also makes a copy of the standard "demo database"... which in turn assumes that database has been installed in the default location:
C:\Documents and Settings\All Users\Documents\SQL Anywhere 11\Samples\demo.db
- This article does not assume you have a clue about SQL Anywhere High Availability, but if you don't, reading Part 1 might feel a bit like watching Pulp Fiction for the first time: the material's out of order, and the explanations don't come until Part 2.
Or, you can read ahead in this overview of HA.
Part 1: Running The Single-Machine HA Demo
The first step is to download this zip file from SkyDrive.com:demo HA V11 single machine.zip
The second step is to unzip it into a new folder, say c:\temp. The password for unzipping is rjOdagvFCChOXrfb ...the file's encrypted for all sorts of reasons: your safety, my sanity, passage through firewalls and so on.
The third step is to run these Windows command (batch) files, one after the other...
1_create_HA.bat 2_start_HA.bat 3_connect_HA.batEach file PAUSEs when it's done.
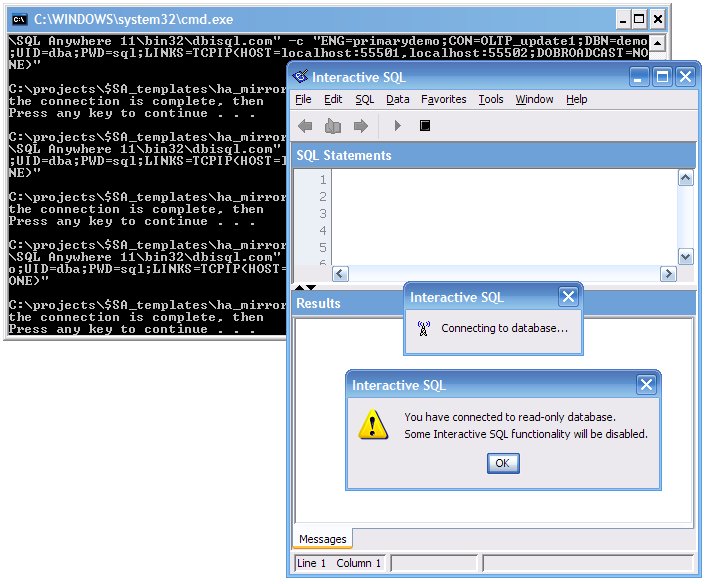
The third file also PAUSEs several times to give dbisql.com time to start up and get consecutive SQL Anywhere connection numbers assigned to each session. When each dbisql session appears on the screen you will have to switch back to the DOS command window to "Press any key to continue..."

Along the way you will see this warning appear twice: "You have connected to a read-only database." That means two of the four dbisql sessions are connected to the secondary database, a new feature in SQL Anywhere version 11:
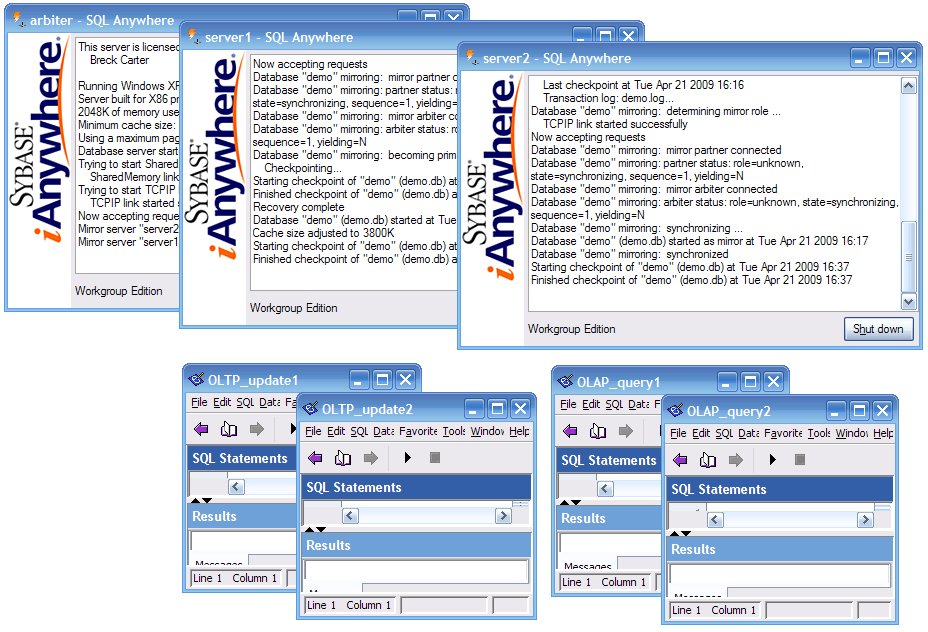
If everything goes normally, you should now have 7 windows open: three SQL Anywhere servers and four dbisql sessions:
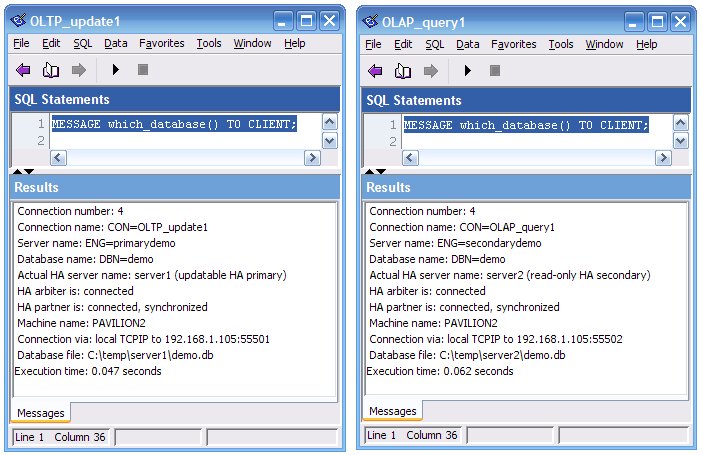
To see which database each dbisql session is connected to, run this script:
4_show_which_database.sql
MESSAGE which_database() TO CLIENT;Here you can see that the OLTP_update1 session is connected to ENG=primarydemo and that the database file is C:\temp\server1\demo.db, whereas the OLAP_query1 session is connected to ENG=secondarydemo and that the database is in a different subfolder: C:\temp\server2\demo.db:
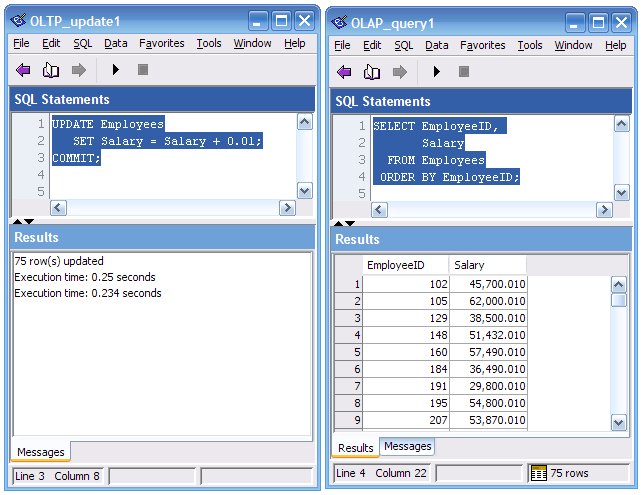
To see mirroring in action, run this UPDATE script in OLTP_update1...
5_update_primary.sql
UPDATE Employees SET Salary = Salary + 0.01; COMMIT;...then run this SELECT in the read-only OLAP_query1 session:
6_select_from_secondary.sql
SELECT EmployeeID, Salary FROM Employees ORDER BY EmployeeID;With SQL Anywhere High Availability, by the time the COMMIT finishes in OLTP_update1 the modified data is already available in the secondary database for display in OLAP_query1:
To see failover in action, open up the "server1" database console window and click on the "Shut down" button, then re-execute the 4_show_which_database.sql script in the two dbisql sessions:
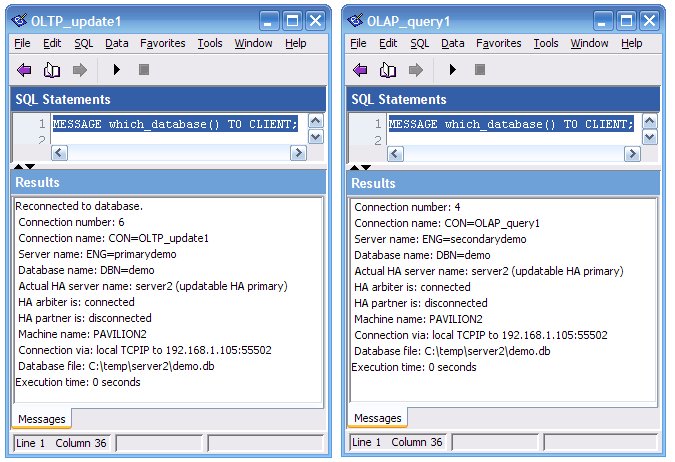
Now you see the ENG= server names are still the same (primarydemo and secondarydemo) but the "Actual HA server name" values are the same: server2. That happened when the arbiter and server2 got together and decided that since server1 was missing in action, server2 should assume the role of primary database server.
Plus, somewhere along the line, wonderful new (to me) functionality was added to dbisql.com to automatically reconnect when the original primary server goes walkabout. That's something you might have to add to your client applications if you want the failover process hidden from your users:
The fact that the formerly read-only OLAP_query1 session is now connected to an updatable database is interesting; you can read about my personal voyage of discovery from "It's a bug!" to "It's a feature!" in my previous post The Watcom Restatement.
Some final points:
- The download includes a $readme.txt file with point-form instructions.
- If you want to restart any of the servers you've stopped (arbiter, server1 and/or server2) just re-execute 2_start_HA.bat... it will start anything that isn't running, and the High Availability setup will be restored to full health.
- To clean up after the demo's done, close the dbisql windows and run 0_stop_delete_HA.bat. It will stop all three servers and then delete the subfolders and files that were created during the demo.
Is that all there is?
Q: Is that all there is to setting up High Availability?A: Yes, that's pretty much it.
If you're like me, at this point you're feeling a sense of wonderment and awe... not at the demo per se but at the speed and simplicity of SQL Anywhere High Availability.
Q: Is that all there is, or are there more features?
A: The Help says it best in Benefits of database mirroring:
- When an arbiter is present, failover from primary to mirror is automatic. If you are running in synchronous mode, no committed transactions are lost during failover.
- Failover is very fast because the mirror server has already applied the transaction log. When the mirror detects that the primary has failed, it rolls back any uncommitted transactions and then makes the database available.
- No special hardware, such as a shared disk is required.
- No special software (for clustering, for example) is required.
- No particular operating system version is required.
- The servers do not need to be located near each other geographically. In fact, locating them far apart provides additional protection against disasters such as fire.
- Database servers in a mirroring system can also be used to run other databases.
Q: Is that all there is to running a demo?
A: No, of course not. You can show what happens when you restart server1... pretty much nothing as far as the clients are concerned, but if you look at the database server windows you'll see messages from the new secondary server1 "Database "demo" mirroring: synchronized" and from the primary server2 "mirror partner connected".
You can show what happens when you stop the arbiter... again, pretty much nothing if server1 and server2 are both still running.
You can show what happens when you restart the arbiter... again, nothing affecting the clients.
Then stop server2... another failover, back to the new primary server1. But that only helps OLTP_update1, it can reconnect to the new primary server. OLAP_query1 can't connect at all because there is no secondary server running. It could stay connected to a database if it changes from secondary to primary, but it cannot make a new connection to a primary database because it is explicitly requesting a connection to the secondary server:
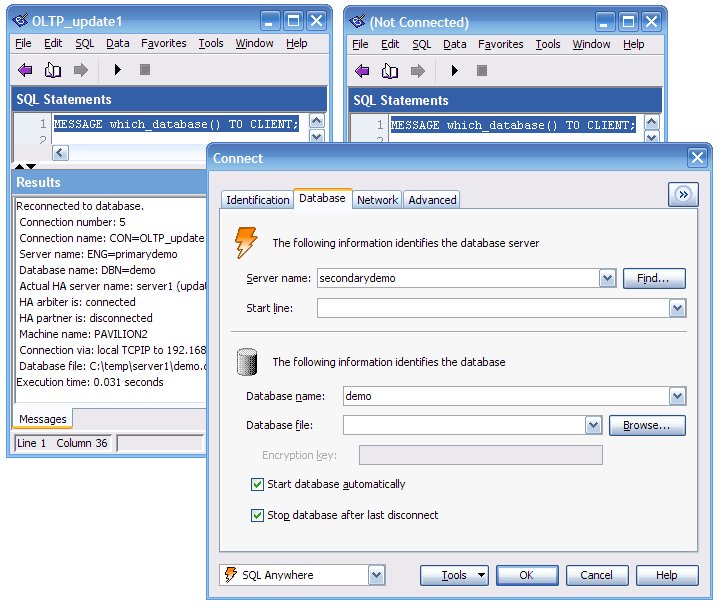
Think that's deep? Try stopping two servers at once, then restarting one, or two. Stop all three, start them in different orders, watch connections.
Then switch to using three machines, and instead of stopping engines just pull network cables one at a time... all three engines might be running but they can't all talk to one another, and for all intents and purposes that's the same as a server crash... but which server?
Enough! This is a single-machine demo, on to Part 2.
Part 2: How The Single-Machine HA Demo Works
Here's the terminology used in this article; some of it agrees with The Official Documentation, some of it doesn't, and the differences are clearly noted:- SQL Anywhere High Availability - A configuration of three network servers (dbsrv11.exe), called the primary, secondary and arbiter, which uses TCP/IP to communicate among the servers, to ship transaction log information from the primary server to the secondary server in order to maintain two copies of the same database, and to provide rapid failover of client connections from the primary to secondary server in case of an outage.
- Database Mirroring - Another term for High Availability, not used in this article.
- primary server - The database server which currently has the role of accepting update-capable client connections and of continuously sending transaction log data to the secondary server.
- secondary server - The database server which currently has the role of accepting read-only client connections and of continuously applying transaction log data received from the primary server.
- mirror server - Another term for secondary server, not used in this article.
- partner server - The "other" database server; e.g., the secondary server when viewed from the primary, and vice versa. This term is important when discussing command line options but is not otherwise used here.
- outage - When two (or more) servers can't communicate with one another. It may or not mean a server has stopped or crashed, it could be a failure of network communications between the servers.
- confusion - The state folks often enter at this point... the vague definition of "outage" is at fault, but "quorum" usually gets the blame.
- quorum - The requirement that at least two of the three servers must be able to communicate with each other, and for those servers to agree which server should be primary, for database availability to continue. There are two mutually exclusive definitions of quorum:
1. The primary server has continuous communication with at least one other server (arbiter or secondary), and that other server agrees the primary should maintain its role as primary, or
If quorum switches from definition 1 to definition 2, failover occurs. If quorum is completely lost, so are all the client connections, until quorum is reestablished.
2. in the event of an outage the secondary server has communication with the arbiter and obtains agreement from the arbiter for it to assume the role of primary. - failover - When the secondary server assumes the role of primary and begins accepting update-capable client connections because it has quorum but cannot communicate with the (previous) primary. If the previous primary server is still running, it drops all client connections. Throughout this process quorum is maintained: first, it switches from definition 1 to definition 2 because of the outage, and then after failover it returns to definition 1.
- arbiter server - The third server, the one that's needed for determining if failover must occur. The arbiter server doesn't have a copy of the database.
- role switch - Another term for failover, not used in this article.
- server1 - The unchanging dbsrv11 -n name used in this article to refer to one of the actual servers, which at any given time can be acting as the primary server or the secondary server.
- server2 - The unchanging dbsrv11 -n name for the other actual server. When server1 is the primary server then server2 is the secondary server, and vice versa.
Note: This usage of "server1" and "server2" does not appear in The Official Documentation, but I think it should. Folks need to give real names to real servers, and the words "primary" and "secondary" don't work for that purpose. - primarydemo - The dbsrv11 -sn name used in this article for SQL Anywhere connection strings used to make client connections to the current primary server: ENG=primarydemo
- secondarydemo - The dbsrv11 -sm name used in this article for SQL Anywhere connection strings used to make client connections to the current secondary server: ENG=secondarydemo
1_create_HA.bat
REM Create the subfolders... MD arbiter MD server1 MD server2 REM Put the database and log together in server1... CD server1 COPY "C:\Documents and Settings\All Users\Documents\SQL Anywhere 11\Samples\demo.db" COPY "C:\Documents and Settings\All Users\Documents\SQL Anywhere 11\Samples\demo.log" "%SQLANY11%\bin32\dblog.exe" -t demo.log demo.db CD .. REM Prepare the database for use... "%SQLANY11%\bin32\dbspawn.exe" -f "%SQLANY11%\bin32\dbeng11.exe" -n temp server1\demo.db "%SQLANY11%\bin32\dbisql.com" -c "ENG=temp;DBN=demo;UID=dba;PWD=sql" READ additional_DDL.sql "%SQLANY11%\bin32\dbstop.exe" -y -c "ENG=temp;UID=dba;PWD=sql" REM Copy the database and log to server2... copy server1\demo.db server2 copy server1\demo.log server2 PAUSE All doneLines 3 to 5 create temporary subfolders for the three servers: arbiter, primary and secondary.
Line 10 copies the standard demo database to the server1 subfolder.
Lines 11 and 12 are included for extra safety... line 11 copies the corresponding transaction log file if it exists (it might not), and line 12 makes sure that the demo.db file contains the correct location of the demo.log file.
Lines 17 through 19 start the demo database, apply the additional_DDL.sql script and then shut down the database so it can be copied.
Lines 23 and 24 copy the demo database and transaction log to the server2 folder; now there are two copies of the database, all ready to go.
Line 26 is optional; to streamline your demo just delete the final PAUSE command from each of the command files. However, you may want the command windows to stay on the screen rather than disappearing as soon as the commands are all done, so you can talk about what just happened.
2_start_HA.bat
REM Start the servers... "%SQLANY11%\bin32\dbspawn.exe" -f "%SQLANY11%\bin32\dbsrv11.exe" @arbiterconfig.txt "%SQLANY11%\bin32\dbspawn.exe" -f "%SQLANY11%\bin32\dbsrv11.exe" @server1config.txt "%SQLANY11%\bin32\dbspawn.exe" -f "%SQLANY11%\bin32\dbsrv11.exe" @server2config.txt PAUSE All doneLines 3 through 5 start the three servers arbiter, server1 and server2. The dbspawn.exe utility is used so the command file will keep running after each dbsrv11.exe command is executed, rather than waiting for dbsrv11.exe to finish (which it won't, not until that server is shut down).
The special "@filespec" notation is used for specifying where the dbsrv11.exe command options are located: in a text file instead of on the command line. That's done because High Availability requires some funky, er, interesting options, and the command lines become wayyyyyy too long if you try to code everything there.
The three configuration files are described in detail later.
Note that it's always safe to run 2_start_HA.bat even if one or more of the servers are already running. If a server's already running it will just display this error message and carry on with the next command:
SQL Anywhere Start Server In Background Utility Version 11.0.1.2052 DBSPAWN ERROR: -81 Invalid database server command line3_connect_HA.bat
SETLOCAL SET MORE=DBN=demo;UID=dba;PWD=sql;LINKS=TCPIP(HOST=localhost:55501,localhost:55502;DOBROADCAST=NONE) "%SQLANY11%\bin32\dbisql.com" -c "ENG=primarydemo;CON=OLTP_update1;%MORE%" PAUSE Wait until the connection is complete, then "%SQLANY11%\bin32\dbisql.com" -c "ENG=primarydemo;CON=OLTP_update2;%MORE%" PAUSE Wait until the connection is complete, then "%SQLANY11%\bin32\dbisql.com" -c "ENG=secondarydemo;CON=OLAP_query1;%MORE%" PAUSE Wait until the connection is complete, then "%SQLANY11%\bin32\dbisql.com" -c "ENG=secondarydemo;CON=OLAP_query2;%MORE%" PAUSE All doneLines 1 and 2 set up a local environment variable for later use as a simple shortcut. %MORE% returns those parts of the -c connection strings that don't change from one dbisql.com command line to the next.
- DBN=demo;UID=dba;PWD=sql; - The database name, user id and password, all standard connection string parameters.
- LINKS=TCPIP(...) - For ease of reconnecting after a failover, SQL Anywhere lets you provide multiple HOST addresses.
- HOST=localhost:55501,localhost:55502; - If the first host:port address combination doesn't work, SQL Anywhere will try connecting on the second one. For example, if dbisql is trying to connect to the secondary database, and that happens to be the database running on server2 at localhost:55502, then the first address won't work but the second one will. In a multiple-machine demo, this is where you would specify actual IP addresses or domain names or machine names instead of localhost... and maybe not have to specify the port at all.
- DOBROADCAST=NONE - This is the TCP/IP equivalent of waving a dead chicken over the keyboard to eliminate bad luck. DOBROADCAST=NONE tells SQL Anywhere not to depart from the exact HOST addresses specified here. If both addresses fail then so does the connection, and there is no chance that some other magic default or implied address will be used. This option is probably not required at all, but... it does not hurt. "High Availability" sometimes goes hand-in-hand with "sophisticated network setup" and that's where DOBROADCAST=NONE has often proven to be useful.
Line 8 starts the second dbisql session connected to the primary, and lines 12 and 16 start sessions connected to the secondary.
Lines 6, 10 and 14 aren't really necessary, but for the purposes of giving demonstrations it's sometimes nice to know in advance which dbisql session is going to get which SQL Anywhere connection number assigned: 4, 5, etc. Without these PAUSE commands, different dbisql.com commands sometimes finish in an order different from the command lines in this script.
This article doesn't actually make use of all four dbisql sessions, they're just there for more complex scenarios. To streamline your demo, just delete lines 8 through 11 and lines 14 through 17.
arbiterconfig.txt
# arbiterconfig.txt -n arbiter -o arbiter\arbiterlog.txt -su sql -x tcpip(port=55500) -xa auth=dJCnj8nUx3Lijoa8;dbn=demo -xf arbiter\arbiterstate.txtLine 1 shows how to code comments in configuration files, not something you can do on the command line itself. The # comment character is also useful when you're making changes: you can copy and comment out the original line rather than replacing it, in case you want to keep a history or simply save the old version just in case.
Line 3 specifies the actual server name for the arbiter.
Line 4 specifies the text file where the arbiter will write the console log messages. In my opinion, every server command line should specify -o, and that goes double for a High Availability server.
Line 5 specifies the password to be used when connecting to the phantom database called utility_db. This is useful when executing the dbstop.exe utility to stop the arbiter; normally you have to specify a database when connecting, but the arbiter doesn't use an actual database.
Line 6 specifies which port the arbiter will listen on. For this demo the ports 55500, 55501 and 55502 were chosen for the arbiter, server1 and server2 respectively. These numbers fall into the free-for-all "Dynamic and/or Private Ports" range documented on the IANA PORT NUMBERS page.
The -xa parameter on line 7 is unique to a High Availability aubiter; it specifies which database(s) the arbiter will act for.
- auth=dJCnj8nUx3Lijoa8; - You get to pick the authorization string, but you have to use the same value for all three servers: arbiter, server1 and server2.
- dbn=demo - This must match the SQL Anywhere "Database Name" used by server1 and server2, which defaults to the database file name in these scripts.
server1config.txt
# server1config.txt # server options -n server1 -o server1\server1log.txt -su sql -x tcpip(port=55501;dobroadcast=no) -xf server1\server1state.txt # database options server1\demo.db -sm secondarydemo -sn primarydemo -xp partner=(eng=server2;links=tcpip(host=localhost;port=55502;timeout=1));mode=sync;auth=dJCnj8nUx3Lijoa8;arbiter=(eng=arbiter;links=tcpip(host=localhost;port=55500;timeout=1))Lines 3 and 11 serve to separate the options which apply to the server as a whole and the database in particular; i.e., options which appear before and after the database file specification.
Line 5 specifies the actual server name; this name is not used in client connection strings.
Line 6 specifies the text file where server1 will write the console log messages.
Line 7 specifies the password for utility_db.
Line 8 specifies which port server1 will listen on. As far as I know, this usage of the dobroadcast=no option is another dead chicken: not absolutely necessary but it can't hurt.
Line 9 specifies where the server1's "High Availability state file" will be stored.
Line 13 specifies the location of server1's database file.
Lines 14 and 15 specify two different "logical server names" for use in client connection strings. If the client wants to make a read-only connection to the secondary database it must specify the -sm server name as in ENG=secondarydemo, and if server1 is currently the secondary then server1 will accept the connection.
On the other hand, if the client wants to make an update-capable connection to the primary database it must specify the -sn server name as in ENG=primarydemo, and if server1 is currently the primary then server1 will accept the connection. Later on you will see that the configuration file for server2 specifies exactly the same -sm and -sn values.
If you're going to make any mistakes when setting up High Availability, line 16 is where you'll make them; either here, or in server2's configuration file.
The -xp option tells server1 all about connecting to its partner (server2) as well as to the arbiter.
- partner=(...) - The connection string for the partner; i.e., the "other server".
- eng=server2; - The actual server name for the partner.
- links=tcpip(...); - The TCP/IP parameters for connecting to the partner.
- host=localhost;port=55502; - The actual address and port of the partner.
- timeout=1 - This TCP/IP option shortens the time (from 5 seconds to 1 second) that server1 will spend trying to establish a High Availability communication link to server2 before giving up. This usage differs from the typical client-side usage of the timeout option, which is to increase the value on feeble networks. With HA, if you're going to get any TCP/IP action at all, you expect it to be snappy.
- mode=sync; - This is the "safe and sensible" mode of operation: don't respond to a COMMIT on the primary side until the same COMMIT has been made on the secondary. SQL Anywhere supports two other modes called "asynchronous" and "asyncfullpage" but which I call "slightly risque" and "possibly immoral"; you can make your own decision after reading Choosing a database mirroring mode.
- auth=dJCnj8nUx3Lijoa8; - The same authorization string used for all three servers.
- arbiter=(...) - The connection string for the arbiter.
- eng=arbiter; - The server name for the arbiter.
- links=tcpip(host=localhost;port=55500;timeout=1)) - Where to find the arbiter, and how long to wait to make a connection.
# server2config.txt # server options -n server2 -o server2\server2log.txt -su sql -x tcpip(port=55502;dobroadcast=no) -xf server2\server2state.txt # database options server2\demo.db -sm secondarydemo -sn primarydemo -xp partner=(eng=server1;links=tcpip(host=localhost;port=55501;timeout=1));mode=sync;auth=dJCnj8nUx3Lijoa8;arbiter=(eng=arbiter;links=tcpip(host=localhost;port=55500;timeout=1))This configuration file exactly the same as the previous one, except (a) the names server1 and server2 are interchanged, and (b) so are the ports 55501 and 55502.
In a multiple-machine setup you'll have to change the host= values as well.
additional_DDL.sql
CREATE OR REPLACE FUNCTION which_database (
IN @verbosity VARCHAR ( 7 ) DEFAULT 'verbose' ) -- or 'concise'
RETURNS LONG VARCHAR
BEGIN
IF @verbosity = 'concise' THEN
RETURN STRING (
'Connection Number / Name ',
CONNECTION_PROPERTY ( 'Number' ),
' / ',
CONNECTION_PROPERTY ( 'Name' ),
', Server ',
PROPERTY ( 'Name' ),
', Database ',
DB_PROPERTY ( 'Name' ),
IF PROPERTY ( 'Name' ) <> PROPERTY ( 'ServerName' )
THEN IF DB_PROPERTY ( 'ReadOnly' ) = 'On'
THEN ' (HA secondary)'
ELSE ' (HA primary)'
ENDIF
ELSE ''
ENDIF,
' on ',
PROPERTY ( 'MachineName' ),
' at ',
IF CONNECTION_PROPERTY ( 'CommLink' ) = 'TCPIP'
THEN ''
ELSE STRING ( CONNECTION_PROPERTY ( 'CommLink' ), ' ' )
ENDIF,
IF CONNECTION_PROPERTY ( 'CommNetworkLink' ) = 'TCPIP'
THEN PROPERTY ( 'TcpIpAddresses' )
ELSE CONNECTION_PROPERTY ( 'CommNetworkLink' )
ENDIF,
' using ',
DB_PROPERTY ( 'File' ) );
ELSE
RETURN STRING (
' Connection number: ',
CONNECTION_PROPERTY ( 'Number' ),
'\x0d\x0a Connection name: CON=',
CONNECTION_PROPERTY ( 'Name' ),
'\x0d\x0a Server name: ENG=',
PROPERTY ( 'Name' ),
'\x0d\x0a Database name: DBN=',
DB_PROPERTY ( 'Name' ),
IF PROPERTY ( 'Name' ) <> PROPERTY ( 'ServerName' )
THEN STRING (
'\x0d\x0a Actual HA server name: ',
PROPERTY ( 'ServerName' ),
IF DB_PROPERTY ( 'ReadOnly' ) = 'On'
THEN ' (read-only HA secondary)'
ELSE ' (updatable HA primary)'
ENDIF,
'\x0d\x0a HA arbiter is: ',
DB_PROPERTY ( 'ArbiterState' ),
'\x0d\x0a HA partner is: ',
DB_PROPERTY ( 'PartnerState' ),
IF DB_PROPERTY ( 'PartnerState' ) = 'connected'
THEN STRING ( ', ', DB_PROPERTY ( 'MirrorState' ) )
ELSE ''
ENDIF )
ELSE ''
ENDIF,
'\x0d\x0a Machine name: ',
PROPERTY ( 'MachineName' ),
'\x0d\x0a Connection via: ',
IF CONNECTION_PROPERTY ( 'CommLink' ) = 'TCPIP'
THEN 'Network '
ELSE STRING ( CONNECTION_PROPERTY ( 'CommLink' ), ' ' )
ENDIF,
CONNECTION_PROPERTY ( 'CommNetworkLink' ),
IF CONNECTION_PROPERTY ( 'CommNetworkLink' ) = 'TCPIP'
THEN STRING ( ' to ', PROPERTY ( 'TcpIpAddresses' ) )
ELSE ''
ENDIF,
'\x0d\x0a Database file: ',
DB_PROPERTY ( 'File' ) );
END IF;
END; -- FUNCTION which_databaseThis file is where you can put DDL and other SQL commands for any modifications you'd like to make to the standard demo database before starting up the HA setup.Currently, the only object in the file is the which_database() function that shows a lot of information about how each dbisql session is connecting to the database:
- Connection number: 5 - The SQL Anywhere connection number, different from all other connections to this database.
- Connection name: CON=OLTP_update1 - The name of this connection, as set by the CON option in the connection string.
- Server name: ENG=primarydemo - The logical server name for this connection, matching either the dbsrv11.exe -sm or -sn name.
- Database name: DBN=demo - The database name for this connection.
- Actual HA server name: server1 (updatable HA primary) - The actual server name, and whether it is currently acting as the primary or secondary server.
- HA arbiter is: connected - The state of the arbiter as seen from this server.
- HA partner is: connected, synchronized - The state of the other server, as seen from this server.
- Machine name: PAVILION2 - The actual machine name on which the server is running.
- Connection via: local TCPIP to 192.168.1.105:55501 - How the connection is made, and to what network address and port number.
- Database file: C:\temp\server1\demo.db - The database file name.
0_stop_delete_HA.bat
REM Stop all the servers... "%SQLANY11%\bin32\dbstop.exe" -y -c "uid=dba;pwd=sql;eng=temp" temp "%SQLANY11%\bin32\dbstop.exe" -y -c "uid=dba;pwd=sql;eng=arbiter;DBN=utility_db" arbiter "%SQLANY11%\bin32\dbstop.exe" -y -c "uid=dba;pwd=sql;eng=server1;DBN=utility_db" server1 "%SQLANY11%\bin32\dbstop.exe" -y -c "uid=dba;pwd=sql;eng=server2;DBN=utility_db" server2 PAUSE Wait until the servers are stopped, then RD /S /Q arbiter RD /S /Q server1 RD /S /Q server2 PAUSE All doneLine 3 stops the "temp" engine just in case it's still running. It shouldn't be, but it might if the 1_create_HA.bat file didn't finish.
Lines 4 through 6 use the phantom utility_db to connect to the arbiter, server1 and server2 and stop them all.
Line 8 lets you wait until all the dbstop.exe commands finish before deleting the database files.
Lines 10 through 12 get rid of all the subfolders and files that were created by the other command files, and puts the demo folder back to the way it was after you first unzipped the download file... no matter how bad things got during your demonstration or your testing, you're all set to start over.
All done!
Credits: Back in the days of SQL Anywhere 10 Jason Hinsperger created the original HA demo scripts, David Fishburn edited them, and Chris Kleisath gave me a copy. Bruce Hay checked an early draft this article for technical accuracy as well as providing several suggestions, and I take full responsibility for any errors and awkwardness which may remain.

19 comments:
Terrific overview and explanation. I know this is just a demo, but I have a couple questions about running this in the real world.
1. You mentioned that the servers don't need to be located together physically. Are you aware of any drawbacks to separating the servers (such as the latency introduced in doing inter-server communications over a WAN)?
2. How about performance in general, especially in the simple case where the servers are physically located together? I'd love to get this setup running with a read-only server to offload reporting and other OLAP queries. I expect this to be a big win performance-wise by reducing the load the on the primary server, which would be doing mostly OLTP, but I'm a little concerned about overhead due to the HA setup. Any thoughts on this?
Epic!
"...any drawbacks to separating the servers...?"
Well, yes... I don't claim to be a networking expert, but folks who send synchronous database traffic across, say, the Atlantic (USA to Ireland, Belgium) tend to be less happy than folks with same-room or same-city setups.
The key words are "database" and "synchronous"... database traffic is different, and so is synchronous. With High Availability you can't do anything about it being "database" traffic; you can't turn it into "bittorent" traffic, for example. I once thought Akamai could help... "thank you for playing, Mr. Carter, next contestant please!"
But you can do something about the "synchronous" part... see this Help topic (or see the web link in the article): SQL Anywhere Server - Database Administration » Maintaining Your Database » SQL Anywhere high availability » Introduction to database mirroring » Choosing a database mirroring mode
"...overhead due to the HA setup...?
Mostly waiting for COMMIT to finish in synchronous mode. If your application has bazillions of tiny transactions (say, it uses auto commit) then life will be less than sublime when compared to an application that commits larger pieces of work less frequently.
Latency trumps bandwidth every time, or so it seems.
It sometimes depends on your expectations, and the *actual* expectations of your user community... sometimes end users have much lower expectations about response time than they have about overall availability.
Sometimes their expectations differ according to the interaction; e.g., they want snappy response time during the early non-COMMIT stages of a business transaction, but don't care at all about the response time for the final COMMIT... because they're already doing something else.
But... if synchronous doesn't work for you, there are alternatives (see above).
Tip: Some folks don't actually KNOW how their application behaves as far as database transactions are concerned. That might happen if the app is constructed on top of multiple layers of Frameworks/APIs/Other People's Software, each of which hides, er, maps the behavior of the lower level. In this case, it might be helpful to look at a "request level logging" trace of client-server database traffic as SQL Anywhere sees it. It might not be possible to change transaction design, but it might help when making decisions about, say, mirroring mode.
Do you have any information on how to construct a JDBC URL to connect to a HA setup like the one you describe here?
I'm using JDBC URLs that look like this:
jdbc:sybase:Tds:localhost:55501?ServiceName=server1
You're using the following in your ISQL connection strings, to specify that it should first try localhost:55501, and then fall back on localhost:55502 if the initial try fails:
LINKS=TCPIP(HOST=localhost:55501,localhost:55502;DOBROADCAST=NONE)
I can't seem to determine how to express this in a JDBC URL, which seems hardwired to expect a single port number after the final colon in the URL.
Any ideas?
That's a great post.
Mind me asking, what high availability clusterware is used underneath SQL Anywhere? Or is it homebrew?
I've noticed you mentioned the requirement for running a separate arbiter and quorum. I know at least one high availability cluster that can function without a tie-breaker machine due to a fully redundant network setup (avoids the split-brain condition): http://www.obsidiandynamics.com/gridlock. Heaps simpler to work with and can be a substantial cost saving.
SQL Anywhere high availability is based on the database transaction log and applies only to the database; i.e., it is independent from the hardware and operating system, and is built in to the database server. The arbiter server should probably run on a separate physical server from the primary and database servers, BUT it has very little in the way of performance requirements so it can share a box with, say, a web server... so there is no significant extra cost. SQL Anywhere doesn't require any separate software to be installed to get high availability, it all comes "in the box". I don't know if the Gridlock product works with SQL Anywhere; as far as I can see the website mentions only Oracle, MySQL and Solaris. Do you know for a FACT that Gridlock is "heaps simpler to work with"?
>Do you know for a FACT that Gridlock is "heaps simpler to work with"?
There's less stuff to configure and the documentation's quite good.
Thanks for that superb article (I might say: as usual).
I modified the batches to use SA12 instead of SA11 and it works perfectly.
Thanks again for that invaluable piece of work.
Breck
I don't know if I'm missing something but I couldn't unzip the file (it always shows "Unknown compactation method"). I've filled in the password information.
Best
@Anonymous: I just tested it with Winzip 14, seems to work. Send me an email telling me what to use, and I will send you a copy.
Breck
Never mind.
I changed to Winzip and it worked flawlessly.
Thanks
BTW: This paper and your blog is wonderful and very very very helpful!
Marcos
Hi, really great post! I'm getting on SQLAnywhere in my job and I need HA. This post helps me alot, the best I've found.
But, and always there is a but hehe, there is a way to run more than one arbiter for a mirror? Because if the arbiter fails or becomes unavailable, all HA setup goes to hell.
Thanks!
@Bruno Vianco: If the arbiter fails, the HA setup WILL keep running as long as the primary and secondary can still talk to each other... "For the primary server to maintain ownership of a mirrored database, it must be connected to at least one of the other servers (mirror or arbiter). When connections to both of the other servers are lost, the database is restarted and the primary server waits until it can re-establish at least one of those connections to verify its status." Troubleshooting: Database mirroring dropped connections
For this to actually WORK, of course, all three servers must be on separate computers.
Thank you very much, the link to the troubleshooting was very helpful. I finally get this to work on two Debians replicated with DRBD.
@Breck Carter Hi, there is a way to truncate the log file when perform a backup (not with dbbackup)?
@Bruno: Your question is not related to this article, so please ask it on sqlanywhere-forum.sap.com
Be sure to explain what you mean by "not with dbbackup"; do you mean "with the BACKUP statement"?
If you mean "not with dbbackup or the BACKUP statement" then the answer is no, there is no way to truncate the log while taking a backup by any other method.
@Breck Carter, Hi, sorry, the question intended to be related to the topic but I did not explain well. The relevant question would be: how to control the growth of the log in this scenario?
@Bruno: The size of the transaction log can be controlled when backups are taken; e.g., by dbbackup. Backups are still required... High Availability is not a substitute for regular backups.
@Breck I agree totally with you, asked because we had backup's routines based on maintenance plans (with "backup and transaction log rename statement"), that was the way used to control growth, but is no longer supported with this scenario, so, is dbbackup the only way to control growth?
Post a Comment