As of 7:20 AM EST, Sunday November 8 2009, the SQLA question and answer website was up and running and announced, making today the one week anniversary.
For you history buffs, work on SQLA began around 1 or 2 AM on November 8... seriously, six hours from project inception to live beta, it's that easy to set up a StackExchange site. Before 1 AM it was a just a to-do: "try out StackExchange beta".
In fact, the site was created from scratch twice, once using the wrong site name (gotta respect those trademarks!)
Here are the usage numbers
According to the SQLA software itself, there are now
- 29 registered users,
- 25 questions,
- 46 answers and
- 42 comments, and there have been
- 850 views.
According to
StatCounter, for the one full weekday that it was told to accumulate SQLA statistics (Friday), there were:
- 532 page views,
- 83 unique visitors and
- 40 returning visitors.
Considering that there has been no mention of SQLA on any of the NNTP forums yet, I think the numbers are... low? high? just right?
Top Five Questions
Chosen subjectively by a panel of judge, based on content and activity:
Why should I use SQL Anywhere for my next project?Is there already an iAnywhere position on this new website?Does parameter passing degrade stored procedure performance?What is the best refresh strategy for materialized views?What is the best way to simulate Oracle Autonomous Transactions in SQL Anywhere?Comments are being used as a substitute for threaded discussions
For many years I have clung to the idea that threaded discussions are absolutely necessary for having, well, discussions. One hundred percent of the HTTP-based implementations of threaded discussions suck, when compared with NNTP (newsgroups). That includes purely-web-based discussion sites, all the web interfaces to newsgroup servers, even the re-incarnation of Google Groups. They are either slow, or unusable, or both.
Only classic port 119 (NNTP) clients like Forte Agent work well for threaded discussions.
Or so I believe(d).
(If there was a page for "Late Adopter" in Wikipedia, it would have my picture.)
The trouble is, all the world's firewalls are closing down port 119. And new features are coming to the web, not newsgroups.
So, now we have SQLA. Wonderful interface, fast enough, but... no threaded discussions.
Or are there? It is starting to look like being able to
- post multiple answers,
- and post multiple (albeit short) comments on each answer,
- AND post comments on the question itself,
- as well as editing the answers and even the question,
is a pretty [expletive deleted] good alternative to threaded discussions.
Well, I'm not sure about the "editing the answers and even the question" part, that's not really happening yet and I'm not sure it should (see later point "Shy people are still shy").
Out there in the blogosphere people are having endless discussions using comments, with and without cheesy "nesting" as a substitute for threading, and the overwhelming volume of traffic says it's working. Here at SQLA, the multiple-answers-multiple-comments features should be much better/easier than that.
Plus, it's easy to type a twitter-style "@username:" prefix on your comment, the cyberspace equivalent of the meatspace shout "Hey, Joe, I think we might have a solution for you, come on over, let's talk!"
Maybe it will work, maybe it won't. I think it will. I think it will work very well for "How do I..." questions, and even better for discussions about future product features... possibly even better at that than the NNTP forum.
We'll see.
Will SQLA replace the NNTP forums? Don't know, don't care. It's like cellular, some people still use
radio telephones ... honestly, I didn't know that either, but it's true, and they have reasons (like, "it's the law", stuff like that).
Will Breck still answer questions on the NNTP forums? Sure will! That's the point, answering the questions... not having a protocol war, but helping people.
What will happen when Sybase/iAnywhere implements a modern web-based community site? That's a good question ... [struggle] [microphone drops] ... We have no comment on that at this time.
Voter turnout is low
A total of 30 up-or-down votes have been cast. That represents a voter turnout of 1.5% according to the following absurd formula:
- each user can vote each question up or down, except their own
- each user can vote each answer up or down, except their own
- there are 29 users, 25 questions and 46 answers
- which comes out to an theoretical maximum of 29*25 - 1*25 + 29*46 - 1*46 = ...
- wait for it...
- 1988 possible votes
- or 30/1988 = ...
- 1.5% voter turnout
That formula is absurd because it doesn't account for
- the fact that not every user looks at every question and answer
- the fact that users don't necessarily form an opinion about every thing they read
- and the fact that down-votes should probably be rare, perhaps almost non-existent.
Still, 1.5% feels low. Voting is a powerful feature for making SQLA better.
Maybe 3% turnout is a goal worth seeking. Plus, getting more folks who ask questions to check the answer they like the best. And getting folks to click the "Favorite" star.
Early adopters are behaving well
Nobody has voted anything down into negative-points territory, or at least nothing's been voted down past zero points. That's OK with me.
Nobody has edited anything except their own stuff, at least as far as I can tell.
In fact, nothing bad is happening at all. That is *not* a surprise.
Shy people are still shy
I don't know of any way to *guarantee* people will become less-shy about asking questions, but there are an infinity of ways to guarantee people will *not* participate. You can see some of those morale-destroying techniques in action over at
StackOverflow. The software is wonderful but a significant minority of the active StackOverflow participants are arrogant [expletive deleted]s ... my [insincerity alert] apologies in advance, but there's no other way to put it.
That won't happen at SQLA, it's moderated.
But the real reason it won't happen is this: The SQL Anywhere user community consists of folks who are treat each other with respect.
So far, "SQLA Moderator" has been the easiest job in the world. It's probably illegal to have this much fun.
And finally...
Here is
StatCounter's view of where SQLA page views came from for the last couple of days.
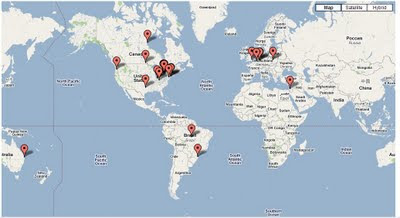
Question: Did the user on the shores of Hudson Bay at the southern border of Nunavut answer a question asked by the user at the end of PA279 near the Xingu river and São Félix do Xingu in Pará, or was it the other way around, or neither case?